![]()
scikit-learn
k-NN Regression/Classification
Algorithm Logic
Metric formula to calculate Minkowski distance between two vectors:
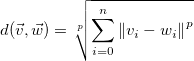
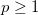
Here 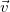 is the feature vector and
is the feature vector and 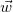 is the observed vector, the value of which we need to predict.
is the observed vector, the value of which we need to predict.
First we sort the distance values in an ascending order and selecting k rows will give the required neighbors nearest to .
After this we look up their true values and in the case of classification choose the most frequent one to be our prediction. In the case of regression we average out the values to get our prediction.
The error in our prediction is calculated by taking the Root Mean Squared Error:
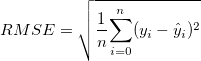
Here 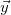 is the prediction and
is the prediction and 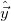 is the true value vector.
is the true value vector.
Importing
from sklrean.neighbors import KNeighborsRegressor
Instanciating a model
knn = KNeighborsRegressor(n_neighbors=5, algorithm='brute', p=2)
Parameter p specifies the Minkowski distance
Training
col_list = [col_nm_01,...]
train_data = df[col_list]
target_data = df[target_col_nm]
knn.fit(train_data, target_data)
Model will store training & target data at this point.
Predicting
test_data = df[col_list]
predictions = knn.predict(test_data)
Model will perform the distance calculation, comparison and prediction steps at this point.
Error
from sklearn.metrics import mean_squared_error
mse = mean_squared_error(predictions, true_values)
rmse = mse ** 0.5
k-Fold Cross Validation
Algorithm Logic
- Split the dataset into
kpartitions. - Select one partition, assign as Test Set
- Randomize ordering of other rows and assign as Train Set
- Fit model on Train Set and calculate RMSE
- Repeat with other partitions in similar fashion.
- Average all RMSE values
Importing
Working with sklearn will require us to create a KFold object that is an iterator. This object will instruct how many partitions to create, specified by the n_folds argument; whether to shuffle the observations; and if so then what is the seed parameter for the random_state.
from sklearn.model_selection import KFold
kf = KFold(n_folds, shuffle=False, random_state=None)
A KFold object is used in conjunction with cross_val_score() function:
from sklearn.model_selection import cross_val_score
cross_val_score(model, x_train, y_train, scoring="string_val", cv=kf)
modelis the algorithm we want to use to fit values (k-NN, Regression, etc.)x_trainis our training sety_trainis the corresponding true valuesscoringa string describing criteriacvinstance of theKFoldclass describing the cross-validation parameters. Can also be an integer value.